In Defense of OOFP

This article is about OOP hierarchies, in comparisson with type classes, using as example Scala’s standard collections, which are involved in a recent debate around their redesign.
1. Background #
Scala is a hybrid language, being at the same time its greatest strength and weakness.
The collection-strawman represents a redesign of Scala’s standard collections, planned to be shipped in Scala 2.13, as part of a Scala Center proposal.
There are at the moment of writing two blog posts explaining the upcoming changes on Scala’s blog:
- Tribulations of CanBuildFrom
- Let Them Be Lazy!
- Scala 2.13 Collections Rework
- On Performance of the New Collections
It’s now also receiving some criticism. This article represents my 2¢ on why I like this redesign and on why criticism of an OOP hierarchy are not warranted, even if you love FP.
1.1. My Road to Scala #
Like many others in the Scala community, I was attracted to Scala because it seemed to be a better, more expressive language, with stricter static type checks than Java or the other languages I worked with. Coming from Python at that time, Scala seemed like a breath of fresh air.
Yes, I came to Scala in 2012 looking for a better OOP language and what I got was a great combination of Smalltalk-esque OOP features, mixed with an actual FP culturre. I have an article about what I liked about it written back then and to be honest, not much has changed.
But what really sold me were the standard collections. In spite of their internal complexity and problems being leaked at the call sites, it was the first time I felt my needs for standard data structures were met and even exceeded.
2. Criticism #
There’s plenty to complain about in the current implementation and here I’m doing my best to summarize it:
2.1. CanBuildFrom #
Checkout this classic StackOverflow issue:
Is the Scala 2.8 collections library a case of “the longest suicide note in history”?
In it the author rightfully complains that this method signature for
List is scary and he doesn’t understand it:
def map[B, That](f: A => B)(implicit bf: CanBuildFrom[Repr, B, That]): That
The Scala core developers first tried to hide this signature, so if you’ll take a look at the current ScalaDoc for List.map, you won’t see it. But that’s only a documentation trick, because the actual source-code (and your IDE) tells a different story, see List.scala#280.
In essence CanBuildFrom is a clever abstraction, as
Martin Odersky himself
explains, however at this point we can all agree that its complexity
is not justified. Not only because it is difficult to understand, but
because it has historically created issues for people at the call-sites.
Here’s what Coda Hale was writing back in 2011:
“ Replacing a `scala.collection.mutable.HashMap` with a `java.util.HashMap` in a wrapper produced an order-of-magnitude performance benefit for one of these loops. Again, this led to some heinous code as any of its methods which took a `Builder` or `CanBuildFrom` would immediately land us with a mutable.HashMap. (We ended up using explicit external iterators and a while-loop, too.)
...
The number of concepts I had to explain to new members of our team for even the simplest usage of a collection was surprising: implicit parameters, builder typeclasses, "operator overloading", return type inference, etc. etc. ”
But if you’ll take a look at List.scala in collection-strawman, that signature now looks like this:
def map[B](f: A => B): List[B]
There, that brings justice to everybody that complained for all these years.
TL;DR: CanBuildFrom was a clever solution to an exaggerated
problem, but you’ll no longer have to worry about it. Beware of clever
solutions to problems you don’t have!
2.2. Complex Hierarchy #
This is an awesome infographic, showing how complex the implementation is for List, by Rob Norris:
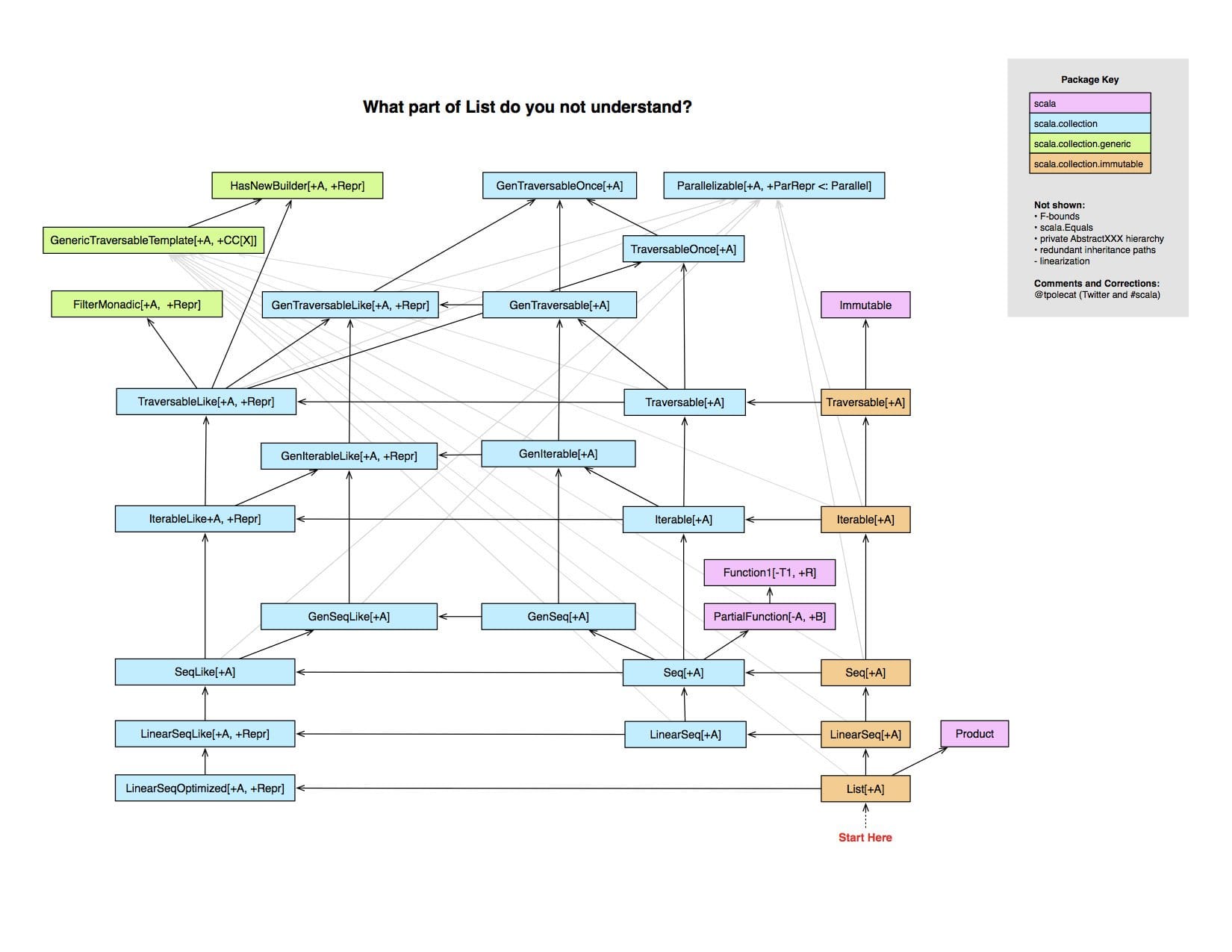
This is indeed a disaster, there’s no nicer way of saying it.
And this is List, after the collection-strawman refactoring:
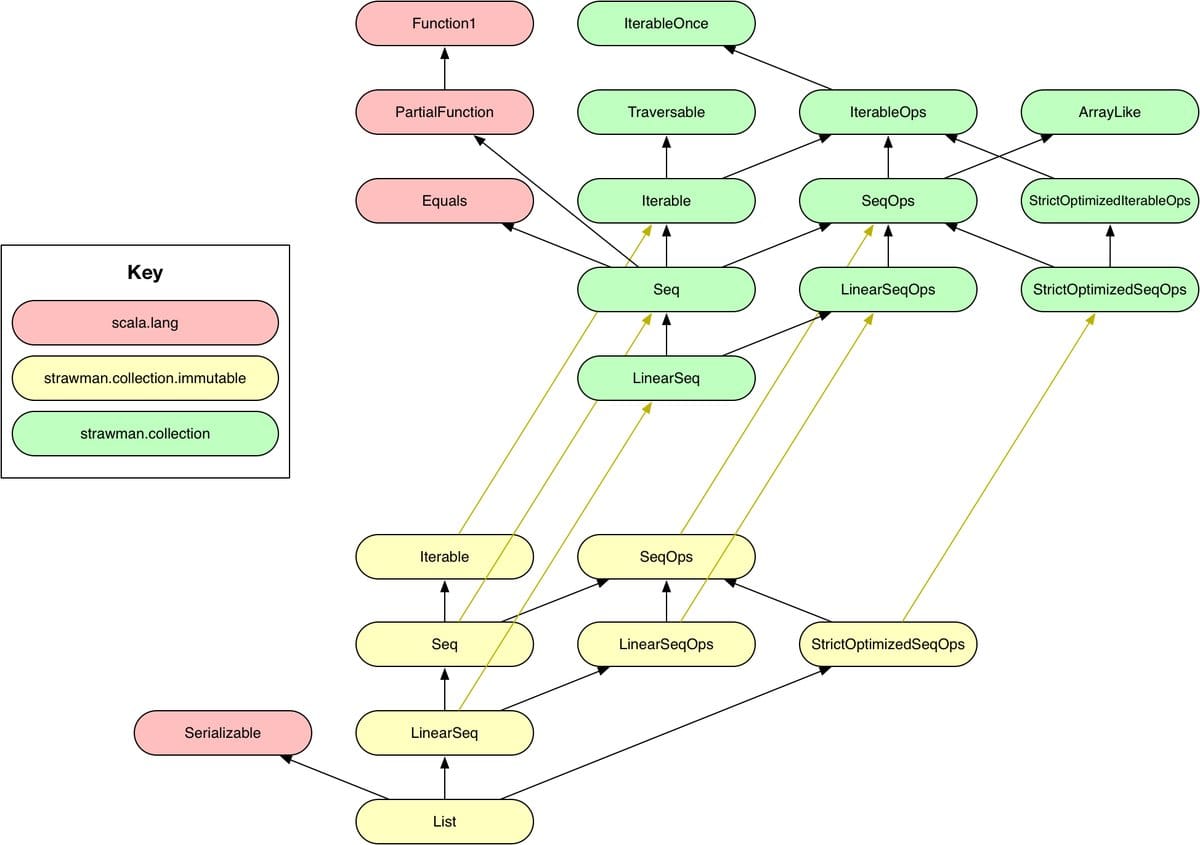
(Again credit goes to Rob Norris)
This is indeed vastly simplified and actually understandable.
Some questions are left to be answered. Just by looking at this info-graphic I wonder in what capacity is there still code sharing between the immutable collections and the mutable versions, or between the lazy and the strict - ideally there should be no code sharing between mutable or immutable, between lazy and strict and I hope they’ve been extra careful this time around.
TL;DR: a complex OOP hierarchy, as clever as it may be, brings with it complexity beyond reason and is counter-productive for subtype polymorphism!
2.3. Seq or Other Super-types #
Daniel Spiewak made a good attempt at a proposal in 2015.
Here are some recent impressions, as a short introduction to this criticism:
“ You always care about the asymptotic properties of your data structures. So there is never a case where Seq makes sense, even as a concept! ”
The example that Daniel gives in his proposal is this:
def foo(is: Seq[Int]): MyThingy = {
val t = new MyThingy
for (idx <- 0 until is.length) {
t.accumulate(is(idx))
}
t
}
“If I showed you this code and asked you what the big-O complexity of it was, could you tell me the answer? No, you cannot, because it depends on the runtime type of
is!”
This is a very good example showing a very frequent booby trap for beginners that aren’t paying attention to their data structures.
He goes on saying:
“Choosing a collection is a very deliberate and intentional thing. We want to select our collection to match the complexity bounds of our problem. Encouraging (and even enabling!) users to work in terms of generic types that throw away this information is wrong, and very very much an anti-pattern.”
I very much respect this opinion and I know from where he’s coming from, however I disagree with it.
Choosing a collection type means committing to an implementation, it means specializing, which is a bad idea in many cases. And arguing against this is also like arguing against Haskell’s Traversable (cats.Traverse).
N.B. we are not arguing against the merits of Haskell’s Traversable
type class and how that compares with Iterable. More on that below.
TL;DR: OOP interfaces might expose leaky operations that
are booby traps (e.g. Seq indexing), but this is not specific
to OOP interfaces, vigilance in design is always needed!
2.4. Not Using Type-classes #
This is actually a separate argument that does have merit:
“ I'll stick to scalaz's separation of functionality and implementation through typeclasses... it's much easier to understand, faster, and easier to extend. ”
“ You do not need a top-down hierarchy of collections. They're ready to break back compatibility, so why not do it right like Spiewak's suggestion 3 years ago? `Builder` and `IterableOnce` are symptoms of a deeper problem: poor design choices. ”
The argument for those amongst you not familiar with it is that type-classes can yield a better design for the standard collections, instead of an OOP hierarchy of interfaces.
To re-use the example above:
import cats.Foldable
def foo[F[_] : Foldable](list: F[Int]): MyThingy =
implicitly[Foldable[F]].foldLeft(list, new MyThingy)(_ accumulate _)
Ah, now we are getting somewhere. But the astute reader should notice at this
point that this means exposure of an extra F[_] type parameter that
you don’t actually need with OOP — well, OK, this syntax heaviness is
an artifact of the Scala language, as in Haskell this wouldn’t be an
issue.
Also, not clearly visible here is that type-classes such as Foldable
or Traversable, while more generic are also strictly less capable
than Iterable. Yes, that’s because of Iterator’s side effecting,
but highly efficient and flexible protocol. More on that below.
TL;DR: type-classes are nice, playing well with parametric polymorphism, but in Scala the syntax is heavier than when using OOP, although this isn’t an issue with Haskell
3. OOP vs Constrained Parametric Polymorphism (Type-classes) #
Lets imagine a function that sums up numbers:
import scala.math.Numeric
def sum[A](list: Seq[A])(implicit A: Numeric[A]): A =
list.foldLeft(A.zero)(A.plus)
Note we are already using Numeric, which is a type class exposed by
Scala’s standard library. And it’s actually not the best type class we
could use, as what we’d need here is a
Monoid,
but ignore that.
Meet Haskell’s Data.Foldable, also described in cats.Foldable.
With it we can fold arbitrary data-structures, e.g. we could sum up numbers:
import cats.Foldable
import scala.math.Numeric
def sum[F[_], A](list: F[A])
(implicit F: Foldable[F], A: Numeric[A]): A = {
F.foldLeft(list, A.zero)(A.plus)
}
(N.B. using F and A as the type names and as the name of the
implicit parameters is nothing special, just a convention)
Is this better?
- PRO: describing
foldLeftas a method onF[_]is no longer required, which makesF[_]data types more generic, more reusable; not very clear in this case, but if you’re unfamiliar with type-class based design, trust me on this one - CON: this method makes
F[_]clearly visible, exposing it at the type system level - this is no longer subtyping, this is no longer the Liskov substitution principle, this is parametric polymorphism and it moves the dispatch cost at compile time, with both the good and the bad
TL;DR: With Scala you can actually pick and choose the best approach - this can lead to choice paralysis however and lots of drama!
4. Case Study: Monix Iterant #

At Scala World I had a talk titled
A Tale of Two Monix Streams
in which I described the design of the upcoming monix.tail.Iterant.
It’s a wonderful data structure for modelling streams that makes use of type-classes defined in cats-effect for being able to describe asynchronous computations. In the presentation I describe how I made use of type-classes, with actual restrictions placed on the operations themselves.
If you’re a beginner in FP design via type-classes, I highly recommend the second part of the presentation.
Here’s the gist - suppose we want a pure
Iterator
that is also capable of deferring the evaluation to a given F[_]
(e.g. monix.eval.Task, cats.effect.IO), such that it’s also
capable of streaming events from asynchronous sources, we could
describe it like this:
sealed trait Iterant[F[_], A]
case class Next[F[_], A](first: A, rest: F[Iterant[F, A]], stop: F[Unit])
extends Iterant[F, A]
case class Suspend[F[_], A](rest: F[Iterant[F, A]], stop: F[Unit])
extends Iterant[F, A]
case class Halt[F[_], A](error: Option[Throwable])
extends ITerant[F, A]
This is a data structure that resembles List, but that:
- defers evaluation to an
F[_]data type that’s capable of suspending side effects, but note that the actual type class restrictions are not defined on the data structure itself - is capable of asynchronous processing, in case
F[_]is capable of asynchronous processing (thus also being equivalent to the async iterators in JavaScript or Ix.NET) - is lazy, if
F[_]is lazy, thus being equivalent to Scala’s Stream, or Java’s Stream - is able to do resource handling, to close any open connections in
case of interruption (by following
stop), thus making it safer than plain iterators
4.1. Type-classes For Super Powers #
So how can this simple data structure possibly have such super powers?
The answer is that it defers the hard work to any F[_] data type
whose capabilities are defined via type classes.
import cats.effect.Sync
def map[F[_], A](fa: Iterant[F, A])(f: A => B)
(implicit F: Sync[F]): Iterant[F, B] = {
def loop(current: Iterant[F, A]): Iterant[F, A] =
current match {
case Next(a, rest, stop) =>
Next(f(b), rest.map(loop), stop)
case Suspend(rest, stop) =>
Suspend(rest.map(loop), stop)
case Halt(e) =>
Halt(e)
}
loop(fa)
}
That part about “implicit F: Sync[F]”, that’s the restriction we
have for F[_], defining its capabilities.
What we need here is for F[_] to implement a map operation and
thus it needs to have a
Functor
instance, however our map is used in fact recursively and due to
Scala being a strict language, if this map were to be strictly
evaluated, then we’d
end up with a stack overflow.
This is why we require cats.effect.Sync, which implies a Functor,
because Sync now suspends evaluation in map by law.
You can see how this process goes: you only add the restrictions you want on the operations themselves, depending on your needs, not on the data structure, thus making the data structure more reusable.
IMPORTANT: F gets exposed via the type system at compile
time. It’s should be obvious that given F and G, then an
Iterant[F, A] cannot be composed with an Iterant[G, A]. So an
Iterant[Task, A] (see
Task) cannot be composed
with an Iterant[Coeval, A] (see
Coeval), or with an
Iterant[IO, A] (see
IO),
unless you convert between these data types explicitly.
For example this should trigger a compile time error:
val tasks: Iterant[Task, Int] = ???
val ios: Iterant[IO, Int] = ???
// Nope, can't do this ;-)
tasks ++ ios
TL;DR: constrained parametric polymorphism via type-classes can give you super powers by effectively outsourcing the processing to pluggable data types with various capabilities, the restrictions being on the operations themselves!
4.2. Liskov Substitution Principle: OOP Strikes Back #
That last example should make you think - parametric polymorphism implies:
- exposing
Ftype parameters at compile time - homogeneity
Because on top of Scala we are looking for opportunities to optimize
performance, due to the runtime not being optimized for laziness and
IO data types (like Haskell), we want to process items in batches,
where possible. For example we’d like to stream arrays, because arrays
are contiguous memory blocks and if you don’t find ways to work with
arrays, then you’re screwed in terms of throughput:
case class NextBatch[F[_], A](
batch: Array[A],
rest: F[Iterant[F, A]],
stop: F[Unit])
extends Iterant[F, A]
But why only arrays? What if we allowed Scala’s List or Vector as
well? There’s no harm in that and it would still have better
throughput, so might as well use Scala’s
Seq:
case class NextBatch[F[_], A](
batch: Seq[A],
rest: F[Iterant[F, A]],
stop: F[Unit])
extends Iterant[F, A]
But wait, because somebody told us that OOP sucks or that the standard
collections should not have a hierarchy, lets use type parameters, like we
did with F:
case class NextBatch[F[_], Seq[_], A](
batch: Seq[A],
rest: F[Iterant[F, A]],
stop: F[Unit])
extends Iterant[F, A]
Oh wait, this doesn’t work, unless we’d expose Seq[_] in Iterant as well:
sealed trait Iterant[F[_], Seq[_], A]
case class NextBatch[F[_], Seq[_], A](
batch: Seq[A],
rest: F[Iterant[F, A]],
stop: F[Unit])
extends Iterant[F, Seq, A]
But this sucks, not only due to the types getting more complicated (your Scala compiler is giving you ugly looks right about now), but also because you can’t have heterogeneity:
val node1 = NextBatch(Array(1,2,3), IO(Halt(None)), IO.unit)
// Ooops, not compatible, List is not Array, will trigger error ;-)
val node2 = NextBatch(List(1,2,3), IO(node1), IO.unit)
No, screw that, let’s backtrack - at this point we need the type class restriction to be on the data structure itself:
case class NextBatch[F[_], Seq[_], A](
batch: Seq[A],
rest: F[Iterant[F, A]],
stop: F[Unit])
(implicit Seq: Foldable[Seq])
extends Iterant[F, A]
That’s better, right?
Wrong - if you’re passing that type-class instance around, that’s effectively a vtable so congratulations, you have an OOP encoding with extra garbage.
TL;DR: with constrained parametric polymorphism you either expose the data type as a type parameter, making types more complicated and saying goodbye to heterogeneity, or you end up with a shitty OOP substitute!
4.3. Iterator vs Foldable and Traverse #
Many people are under the impression that you can substitute the classic Iterator with the Foldable and Traverse type-classes. This is understandable, because these type classes are really potent, really generic, great actually.
Here’s Phil Freeman’s opinion, the creator of the PureScript language:
“ ES2018 will include a whole new language feature in order to implement one instantiation of “traverse”. I’ll say it again - JS won’t be fixed by adding more things. 2ality.com/2017/02/ecmascript-2018.html ”
But that is simply false.
Here’s the big difference: Iterator allows you to pause the
processing, until the current iteration cycle has finished, before
processing the next item, being a pull-based protocol with the user
being completely in charge. The user being responsible for advancing
the cursor to the next item, whenever he wants, in a destructive
manner is also what makes it error prone, but it’s flexible
nonetheless.
So for example, how do you think this works?
val ios: Iterable[IO[Int]] = ???
ios.foldLeft(IO(0)) { (acc, elem) =>
for (a <- acc; e <- elem) yield a + e
}
The short answer - it works, but if that stream is too big, it will blow up your process because there’s no back-pressure in that fold. But I digress.
Iterating over arrays in our NextBatch might prove tricky but is
doable, for example in a mapEval implementation that needs to pop an
item out of our Array, process that in the F[_] monadic context,
then continue from where it left off:
def mapEval[F[_], A](fa: Iterant[F, A])(f: A => F[B])
(implicit F: Sync[F]): Iterant[F, B] = {
def loop(index: Int)(fa: Iterant[F, A]): Iterant[F, B] =
fa match {
case NextBatch(batch, rest, stop) =>
val eval =
if (index >= batch.length)
rest.map(loop(0))
else
f(batch(index)).map { a =>
Next(a, F.pure(loop(index + 1)(fa)), stop)
}
Suspend(eval, stop)
case _ => ???
}
loop(0)(fa)
}
Well, Array can be indexed, but that indexing would be death for
List, isn’t it?
Turns out we have a perfectly capable abstraction for iterating over arrays, lists, vectors or what have you, the classic Iterator:
case class NextCursor[F[_], A](
cursor: Iterator[A],
rest: F[Iterant[F, A]],
stop: F[Unit])
extends Iterant[F, A]
And now we can express this:
def mapEval[F[_], A](fa: Iterant[F, A])(f: A => F[B])
(implicit F: Sync[F]): Iterant[F, B] = {
def loop(fa: Iterant[F, A]): Iterant[F, B] =
fa match {
case NextBatch(batch, rest, stop) =>
loop(NextCursor(batch.iterator(), rest, stop))
case NextCursor(cursor, rest, stop) =>
val eval =
if (cursor.hasNext)
rest.map(loop)
else
f(batch.next()).map { a =>
Next(a, F.pure(loop(fa)), stop)
}
Suspend(eval, stop)
case _ =>
???
}
// Suspends execution, because NextCursor is side-effectful ;-)
Suspend(F.delay(loop(fa)), F.unit)
}
Can you do that with Foldable / Traverse? No, you can’t!
If a tree falls in a forest and no one is around to hear it, is that a
side effect?
The Iterator interface relies on side effects and is thus
incompatible with functional programming. However if its mutation is
properly suspended and encapsulated, such that referential
transparency is preserved, then it really doesn’t matter 😉
To work with type-classes and pure functions, our first intuition should be something like this:
trait IteratorTypeClass[F[_]] {
def next[A](fa: F[A]): Option[(A, F[A])]
}
This is a variation on the state monad, because yes, we’ve got state to evolve.
Here’s the performance characteristics of such a decomposition
for the head and tail operations, needed for this type
class:
- Vector,
has “effectively constant time”, which is worse than
List - Queue
has “amortized constant time”, which is worse than
List - Array
has linear O(N) time for
tail, aka you can change your job now
Yes, Iterator is efficient for all of them, so it wins by a wide
margin. The above is actually horrible and why a type class like
that isn’t popular, because it relies on List’s encoding to be
efficient 😉
So that’s not it. The pure type-class equivalent is actually this:
trait IteratorTypeClass[F[_]] {
type Pointer[T]
def start[A](fa: F[A]): Pointer[A]
def next[A](fa: F[A], cursor: Pointer[A]): Option[(A, Pointer[A])]
}
// Sample instance for Array
object ArrayIterator extends IteratorTypeClass[Array] {
type Pointer[T] = Int
def start[A](fa: Array[A]) = 0
def next[A](fa: Array[A], cursor: Int) =
if (cursor >= fa.length) None
else Some((fa(cursor), cursor + 1))
}
But this will leak implementation details - not bad for our Array
instance, but what if we had some sort of
self-balancing tree
which you then changed to a
HAMT.
In that case our Pointer would be some sort of node with links
to its neighbors, so is it wise exposing it like that? How
is Haskell’s binary compatibility anyway? Does it even support
dynamic linking?
TL;DR: Iterator actually beats pure, type-class
based solution in performance, flexibility or encapsulation! It’s
also lower-level, impure and error prone, but sorely needed sometimes.
5. Seq My Love #
I actually like Seq and have never regretted using it.
Not everybody agrees and as mentioned in section 2.3., there are people advising against its usage:
“ You always care about the asymptotic properties of your data structures. So there is never a case where Seq makes sense, even as a concept! ”
Here’s why I disagree …
5.1. Seq on Return #
Returning Seq from a function gives you the freedom to change the
implementation and this works well because:
- you preserve backwards binary compatibility
- users might only care to traverse it / fold it, which should be an O(n) operation for any sequence
Real use-case from Monix, the Observable.bufferSliding operator:
/** Returns an observable that emits buffers of items it collects from
* the source observable. The resulting observable emits buffers
* every `skip` items, each containing `count` items.
*
* If the source observable completes, then the current buffer gets
* signaled downstream. If the source triggers an error then the
* current buffer is being dropped and the error gets propagated
* immediately.
*
* For `count` and `skip` there are 3 possibilities:
*
* 1. in case `skip == count`, then there are no items dropped and
* no overlap, the call being equivalent to `buffer(count)`
* 1. in case `skip < count`, then overlap between buffers
* happens, with the number of elements being repeated being
* `count - skip`
* 1. in case `skip > count`, then `skip - count` elements start
* getting dropped between windows
*
* @param count the maximum size of each buffer before it should
* be emitted
* @param skip how many items emitted by the source observable should
* be skipped before starting a new buffer. Note that when
* skip and count are equal, this is the same operation as
* `buffer(count)`
*/
final def bufferSliding(count: Int, skip: Int): Observable[Seq[A]] =
liftByOperator(new BufferSlidingOperator(count, skip))
Facts:
- current version (3.0.0-M3) uses an Array as the internal buffer, emitting arrays wrapped in Seq
- version 2.0.0
used a ListBuffer,
thus emitting
Listchunks
The change from List to Array was done:
- without breaking backwards compatibility
- with no consequence to the user, since these chunks are meant to be small and manageable, so all the user cares about is being able to traverse or fold them or to convert them into something else
This is the infamous “program to an interface, not to an implementation” mantra that OOP developers like to repeat so much. You won’t actually need this capability that often, but when you do, it’s golden.
Also note that when using a super-type such as Seq in an interface, due to the
covariance
of return types, you’re always allowed to override with a more
specific type in implementing classes (e.g. to go from Seq to
List), and the Liskov substitution principle still applies.
TL;DR: there are perfectly valid use-cases for Seq as the return type!
5.2. Seq on Input #
The necessity for Seq is the same as for
Foldable,
the need to traverse a collection, aggregating its items into some final result.
Seq also implies that items come in a
sequence in which order
matters and repetition is allowed. For example a
Set
shouldn’t be a Seq, because Set does not allow repetition and has
no ordering.
So here’s another real-world use-case, also from Monix, the Observable.startWith operator:
/** Creates a new Observable that emits the given elements and then
* it also emits the events of the source (prepend operation).
*/
final def startWith[B >: A](elems: Seq[B]): Observable[B] =
Observable.fromIterable(elems) ++ self
Here we might have used an Iterator, however the result wouldn’t have been pure and we might have used an Iterable, but as the author of this operator I felt that the input being a sequence is important for getting back a predictable result - after all, that ordering is important is implied by what this operator does.
And note that all the implementation does is to care about traversal, via
an Iterator loop.
TL;DR: yes, there are perfectly valid use-cases for Seq as the input!
6. Conclusion #
Here’s a summary:
- 2.1. —
CanBuildFromwas a clever solution to an exagerated problem, but you’ll no longer have to worry about it - 2.2. — a complex OOP hierarchy, as clever as it may be, brings with it complexity beyond reason and is counter-productive for subtype polymorphism
- 2.3. — OOP interfaces might expose leaky operations that are
booby traps (e.g.
Seqindexing), but this is not specific to OOP interfaces, vigilance in design is always needed - 2.4. — type-classes are nice, playing well with parametric polymorphism, but in Scala the syntax is heavier than when using OOP, although this isn’t an issue with Haskell
- 3. with Scala you can actually pick and choose the best approach - this can lead to choice paralysis however and lots of drama
- 4.1. — constrained parametric polymorphism via type-classes can give you super powers by effectively outsourcing the processing to pluggable data types with various capabilities, the restrictions being on the operations themselves
- 4.2. — with constrained parametric polymorphism you either expose the data type as a type parameter, making types more complicated and saying goodbye to heterogeneity, or you end up with a shitty OOP substitute
- 4.3. —
Iteratoractually beats pure, type-class based solution in performance, flexibility or encapsulation. It’s also lower-level, impure and error prone, but sorely needed sometimes - 5.1. — there are perfectly valid use-cases for
Seqas the return type - 5.2. — there are perfectly valid use-cases for
Seqas the input
So yes, there will be people out there, such as myself, genuinely enjoying Scala’s OOP and the new collections.
Thanks for reading ️❤️