Asynchronous Programming and Scala
Asynchrony is everywhere and it subsumes concurrency. This article explains what asynchronous processing is and its challenges.
1. Introduction #
As a concept it is more general than multithreading, although some people confuse the two. If you’re looking for a relationship, you could say:
Multithreading <: Asynchrony
We can represent asynchronous computations with a type:
type Async[A] = (Try[A] => Unit) => Unit
If it looks ugly with those Unit return types, that’s because
asynchrony is ugly. An asynchronous computation is any task, thread,
process, node somewhere on the network that:
- executes outside of your program’s main flow or from the point of view of the caller, it doesn’t execute on the current call-stack
- receives a callback that will get called once the result is finished processing
- it provides no guarantee about when the result is signaled, no guarantee that a result will be signaled at all
It’s important to note asynchrony subsumes concurrency, but not
necessarily multithreading. Remember that in Javascript the majority
of all I/O actions (input or output) are asynchronous and even heavy
business logic is made asynchronous (with setTimeout based scheduling)
in order to keep the interface responsive. But no kernel-level
multithreading is involved, Javascript being an N:1 multithreaded
platform.
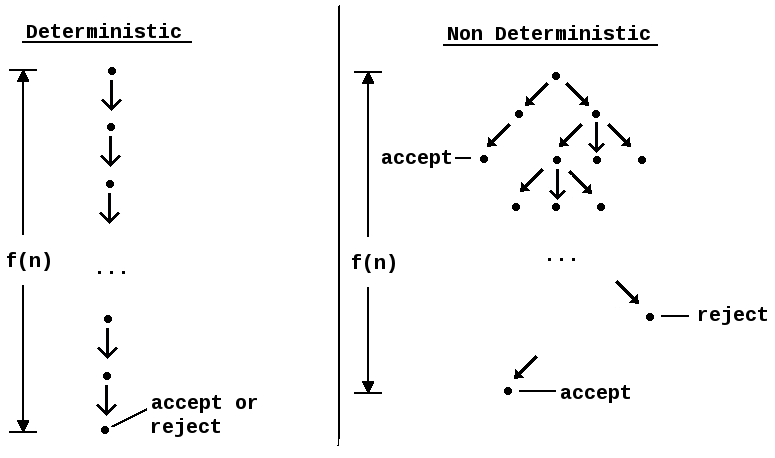
Introducing asynchrony into your program means you’ll have concurrency problems because you never know when asynchronous computations will be finished, so composing the results of multiple asynchronous computations running at the same time means you have to do synchronization, as you can no longer rely on ordering. And not relying on an order is a recipe for nondeterminism.
Wikipedia says: a nondeterministic algorithm is an algorithm that, even for the same input, can exhibit different behaviors on different runs, as opposed to a deterministic algorithm … A concurrent algorithm can perform differently on different runs due to a race condition.
The astute reader could notice that the type in question can be seen everywhere, with some modifications depending on use-case and contract:
- in the Observer pattern from the Gang of Four
- in Scala’s Future,
which is defined by its abstract
onCompletemethod - in Java’s ExecutorService.submit(Callable)
- in Javascript’s EventTarget.addEventListener
- in Akka actors, although there the given callback
is replaced by the
sender()reference - in the Monix Task.Async definition
- in the Monix Observable and Observer pair
- in the Reactive Streams specification
What do all of these abstractions have in common? They provide ways to deal with asynchrony, some more successful than others.
2. The Big Illusion #
We like to pretend that we can describe functions that can convert asynchronous results to synchronous ones:
def await[A](fa: Async[A]): A
Fact of the matter is that we can’t pretend that asynchronous processes are equivalent with normal functions. If you need a lesson in history for why we can’t pretend that, you only need to take a look at why CORBA failed.
With asynchronous processes we have the following very common fallacies of distributed computing:
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn’t change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
None of them are true of course. Which means code gets written with little error handling for network failures, ignorance of network latency or packet loss, ignorance of bandwidth limits and in general ignorance of the ensuing nondeterminism.
People have tried to cope with this by:
- callbacks, callbacks everywhere, equivalent to basically ignoring the problem, as it happens in Javascript, which leads to the well known effect of callback hell, paid for with the sweat and blood of programmers that constantly imagine having chosen a different life path
- blocking threads, on top of 1:1 (kernel-level) multithreading platforms
- first-class continuations, implemented for example by Scheme in call/cc, being the ability to save the execution state at any point and return to that point at a later point in the program
- The
async/awaitlanguage extension from C#, also implemented in the scala-async library and in the latest ECMAScript - Green threads managed by the runtime, possibly in combination with M:N multithreading, to simulate blocking for asynchronous actions; examples including Golang but also Haskell
- The actor model as implemented in Erlang or Akka, or CSP such as in Clojure’s core.async or in Golang
- Monads being used for ordering and composition, such as Haskell’s Async type in combination with the IO type, or F# asynchronous workflows, or Scala’s Futures and Promises, or the Monix Task or the Scalaz Task, etc, etc.
If there are so many solutions, that’s because none of them is suitable as a general purpose mechanism for dealing with asynchrony. The no silver bullet dilemma is relevant here, with memory management and concurrency being the biggest problems that we face as software developers.
WARNING - personal opinion and rant: People like to boast about M:N
platforms like Golang, however I prefer 1:1 multithreaded platforms,
like the JVM or dotNET.
Because you can build M:N multithreading on top of 1:1 given enough
expressiveness in the programming language (e.g. Scala’s Futures and
Promises, Task, Clojure’s core.async, etc), but if that M:N runtime starts being
unsuitable for your usecase, then you can’t fix it or replace it
without replacing the platform. And yes, most M:N platforms are broken
in one way or another.
Indeed learning about all the possible solutions and making choices is
freaking painful, but it is much less painful than making uninformed
choices, with the TOOWTDI and “worse is better” mentalities being in
this case actively harmful. People complaining about the difficulty of
learning a new and expressive language like Scala or Haskell are
missing the point, because if they have to deal with concurrency, then
learning a new programming language is going to be the least of their
problems. I know people that have quit the software industry because
of the shift to concurrency.
3. Callback Hell #
Let’s build an artificial example made to illustrate our challenges. Say we need to initiate two asynchronous processes and combine their result.
First let’s define a function that executes stuff asynchronously:
import scala.concurrent.ExecutionContext.global
type Async[A] = (A => Unit) => Unit
def timesTwo(n: Int): Async[Int] =
onFinish => {
global.execute(new Runnable {
def run(): Unit = {
val result = n * 2
onFinish(result)
}
})
}
// Usage
timesTwo(20) { result => println(s"Result: $result") }
//=> Result: 40
3.1. Sequencing (Purgatory of Side-effects) #
Let’s combine two asynchronous results, with the execution happening one after another, in a neat sequence:
def timesFour(n: Int): Async[Int] =
onFinish => {
timesTwo(n) { a =>
timesTwo(n) { b =>
// Combining the two results
onFinish(a + b)
}
}
}
// Usage
timesFour(20) { result => println(s"Result: $result") }
//=> Result: 80
Looks simple now, but we are only combining two results, one after another.
The big problem however is that asynchrony infects everything it touches. Let’s assume for the sake of argument that we start with a pure function:
def timesFour(n: Int): Int = n * 4
But then your enterprise architect, after hearing about these Enterprise JavaBeans and
a lap dance, decides that you should depend on this asynchronous timesTwo
function. And now our timesFour implementation changes from a pure mathematical
function to a side-effectful one and we have no choice in the matter.
And without a well grown Async type, we are forced to deal with side-effectful
callbacks for the whole pipeline. And blocking for the result won’t help,
as you’re just hiding the problem, see section 2 for why.
But wait, things are about to get worse 😷
3.2. Parallelism (Limbo of Nondeterminism) #
The second call we made above is not dependent on the first call, therefore it can run in parallel. On the JVM we can run CPU-bound tasks in parallel, but this is relevant for Javascript as well, as we could be making Ajax requests or talking with web workers.
Unfortunately here things can get a little complicated. First of all the naive way to do it is terribly wrong:
// REALLY BAD SAMPLE
def timesFourInParallel(n: Int): Async[Int] =
onFinish => {
var cacheA = 0
timesTwo(n) { a => cacheA = a }
timesTwo(n) { b =>
// Combining the two results
onFinish(cacheA + b)
}
}
timesFourInParallel(20) { result => println(s"Result: $result") }
//=> Result: 80
timesFourInParallel(20) { result => println(s"Result: $result") }
//=> Result: 40
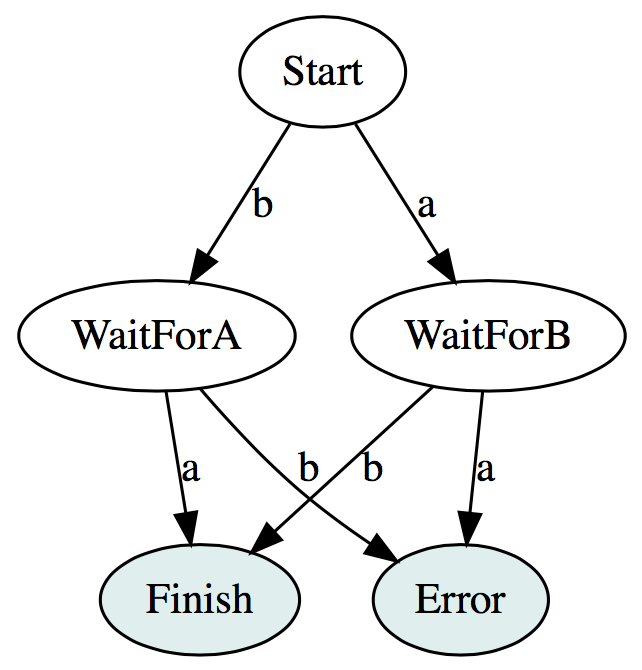
This right here is an example showing nondeterminism in action. We get no ordering guarantees about which one finishes first, so if we want parallel processing, we need to model a mini state machine for doing synchronization.
First, we define our ADT describing the state-machine:
// Defines the state machine
sealed trait State
// Initial state
case object Start extends State
// We got a B, waiting for an A
final case class WaitForA(b: Int) extends State
// We got a A, waiting for a B
final case class WaitForB(a: Int) extends State
And then we can evolve this state machine asynchronously:
// BAD SAMPLE FOR THE JVM (only works for Javascript)
def timesFourInParallel(n: Int): Async[Int] = {
onFinish => {
var state: State = Start
timesTwo(n) { a =>
state match {
case Start =>
state = WaitForB(a)
case WaitForA(b) =>
onFinish(a + b)
case WaitForB(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
}
timesTwo(n) { b =>
state match {
case Start =>
state = WaitForA(b)
case WaitForB(a) =>
onFinish(a + b)
case WaitForA(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
}
}
}
To better visualize what we’re dealing with, here’s the state machine:
But wait, we aren’t over because the JVM has true 1:1 multi-threading, which means
we get to enjoy shared memory concurrency and thus access to that state has to
be synchronized.
One solution is to use synchronized blocks, also called intrinsic locks:
// We need a common reference to act as our monitor
val lock = new AnyRef
var state: State = Start
timesTwo(n) { a =>
lock.synchronized {
state match {
case Start =>
state = WaitForB(a)
case WaitForA(b) =>
onFinish(a + b)
case WaitForB(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
}
}
//...
Such high-level locks protect resources (such as our state) from
being accessed in parallel by multiple threads. But I personally
prefer to avoid high-level locks because the kernel’s scheduler can
freeze any thread for any reason, including threads that hold locks,
freezing a thread holding a lock means that other threads will be
unable to make progress and if you want to guarantee constant progress
(e.g. soft real-time characteristics), then
non-blocking
logic is preferred when possible.
So an alternative is to use an AtomicReference, which is perfect for this case:
// CORRECT VERSION FOR JVM
import scala.annotation.tailrec
import java.util.concurrent.atomic.AtomicReference
def timesFourInParallel(n: Int): Async[Int] = {
onFinish => {
val state = new AtomicReference[State](Start)
@tailrec def onValueA(a: Int): Unit =
state.get match {
case Start =>
if (!state.compareAndSet(Start, WaitForB(a)))
onValueA(a) // retry
case WaitForA(b) =>
onFinish(a + b)
case WaitForB(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
timesTwo(n)(onValueA)
@tailrec def onValueB(b: Int): Unit =
state.get match {
case Start =>
if (!state.compareAndSet(Start, WaitForA(b)))
onValueB(b) // retry
case WaitForB(a) =>
onFinish(a + b)
case WaitForA(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
timesTwo(n)(onValueB)
}
}
PRO-TIP: if you want code that cross-compiles to Javascript / Scala.js, along with performance tweaks and cool utilities for manipulating atomic references, try the Atomic type from Monix.
Are you getting pumped? Let’s take it up a notch 😝
3.3. Recursivity (Wrath of StackOverflow) #
What if I were to tell you that the above onFinish call is
stack-unsafe and if you aren’t going to force an asynchronous
boundary when calling it, then your program can blow up
with a StackOverflowError?
You shouldn’t take my word for it. Let’s first have some fun and define the above operation in a generic way:
import scala.annotation.tailrec
import java.util.concurrent.atomic.AtomicReference
type Async[+A] = (A => Unit) => Unit
def mapBoth[A,B,R](fa: Async[A], fb: Async[B])(f: (A,B) => R): Async[R] = {
// Defines the state machine
sealed trait State[+A,+B]
// Initial state
case object Start extends State[Nothing, Nothing]
// We got a B, waiting for an A
final case class WaitForA[+B](b: B) extends State[Nothing,B]
// We got a A, waiting for a B
final case class WaitForB[+A](a: A) extends State[A,Nothing]
onFinish => {
val state = new AtomicReference[State[A,B]](Start)
@tailrec def onValueA(a: A): Unit =
state.get match {
case Start =>
if (!state.compareAndSet(Start, WaitForB(a)))
onValueA(a) // retry
case WaitForA(b) =>
onFinish(f(a,b))
case WaitForB(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
@tailrec def onValueB(b: B): Unit =
state.get match {
case Start =>
if (!state.compareAndSet(Start, WaitForA(b)))
onValueB(b) // retry
case WaitForB(a) =>
onFinish(f(a,b))
case WaitForA(_) =>
// Can't be caught b/c async, hopefully it gets reported
throw new IllegalStateException(state.toString)
}
fa(onValueA)
fb(onValueB)
}
}
And now we can define an operation similar to Scala’s Future.sequence,
because our will is strong and our courage immensurable 😇
def sequence[A](list: List[Async[A]]): Async[List[A]] = {
@tailrec def loop(list: List[Async[A]], acc: Async[List[A]]): Async[List[A]] =
list match {
case Nil =>
onFinish => acc(r => onFinish(r.reverse))
case x :: xs =>
val update = mapBoth(x, acc)(_ :: _)
loop(xs, update)
}
val empty: Async[List[A]] = _(Nil)
loop(list, empty)
}
// Invocation
sequence(List(timesTwo(10), timesTwo(20), timesTwo(30))) { r =>
println(s"Result: $r")
}
//=> Result: List(20, 40, 60)
Oh, you really think we are done?
val list = 0.until(10000).map(timesTwo).toList
sequence(list)(r => println(s"Sum: ${r.sum}"))
Behold the glorious memory error that will probably crash your program in production,
being considered a fatal error that Scala’s NonFatal does not catch:
java.lang.StackOverflowError
at java.util.concurrent.ForkJoinPool.externalPush(ForkJoinPool.java:2414)
at java.util.concurrent.ForkJoinPool.execute(ForkJoinPool.java:2630)
at scala.concurrent.impl.ExecutionContextImpl$$anon$3.execute(ExecutionContextImpl.scala:131)
at scala.concurrent.impl.ExecutionContextImpl.execute(ExecutionContextImpl.scala:20)
at .$anonfun$timesTwo$1(<pastie>:27)
at .$anonfun$timesTwo$1$adapted(<pastie>:26)
at .$anonfun$mapBoth$1(<pastie>:66)
at .$anonfun$mapBoth$1$adapted(<pastie>:40)
at .$anonfun$mapBoth$1(<pastie>:67)
at .$anonfun$mapBoth$1$adapted(<pastie>:40)
at .$anonfun$mapBoth$1(<pastie>:67)
at .$anonfun$mapBoth$1$adapted(<pastie>:40)
at .$anonfun$mapBoth$1(<pastie>:67)
As I said, that onFinish call being made without a forced async
boundary can lead to a stack-overflow error. On top of Javascript
this can be solved by scheduling it with setTimeout and on top of
the JVM you need a thread-pool or a Scala ExecutionContext.
Are you feeling the fire yet? 🔥
4. Futures and Promises #
The scala.concurrent.Future describes strictly evaluated
asynchronous computations, being similar to our Async type used
above.
Wikipedia says: Future and Promise are constructs used for synchronizing program execution in some concurrent programming languages. They describe an object that acts as a proxy for a result that is initially unknown, usually because the computation of its value is yet incomplete.
Author’s Rant: The docs.scala-lang.org article on
Futures and Promises currently
says that “Futures provide a way to reason about performing many
operations in parallel– in an efficient and non-blocking way”, but
that is misleading, a source of confusion.
The Future type describes asynchrony and not parallelism. Yes, you
can do things in parallel with it, but it’s not meant only for
parallelism (async != parallelism) and for people looking into ways to
use their CPU capacity to its fullest, working with Future can prove
to be expensive and unwise, because in certain cases it has performance
issues, see section 4.4.
The Future is an interface defined by 2 primary operations, along with
many combinators defined based on those primary operations:
import scala.util.Try
import scala.concurrent.ExecutionContext
trait Future[+T] {
// abstract
def value: Option[Try[T]]
// abstract
def onComplete(f: Try[T] => Unit)(implicit ec: ExecutionContext): Unit
// Transforms values
def map[U](f: T => U)(implicit ec: ExecutionContext): Future[U] = ???
// Sequencing ;-)
def flatMap[U](f: T => Future[U])(implicit ec: ExecutionContext): Future[U] = ???
// ...
}
The properties of Future:
- Eagerly evaluated
(strict and not lazy), meaning that when the caller of a function
receives a
Futurereference, whatever asynchronous process that should complete it has probably started already. - Memoized (cached),
since being eagerly evaluated means that it behaves like a normal
value instead of a function and the final result needs to be
available to all listeners. The purpose of the
valueproperty is to return that memoized result orNoneif it isn’t complete yet. Goes without saying that calling itsdef valueyields a non-deterministic result. - Streams a single result and it shows because of the memoization applied. So when listeners are registered for completion, they’ll only get called once at most.
Explanatory notes about the ExecutionContext:
- The
ExecutionContextmanages asynchronous execution and although you can view it as a thread-pool, it’s not necessarily a thread-pool (because async != multithreading or parallelism). - The
onCompleteis basically ourAsynctype defined above, however it takes anExecutionContextbecause all completion callbacks need to be called asynchronously. - All combinators and utilities are built on top of
onComplete, therefore all combinators and utilities must also take anExecutionContextparameter.
If you don’t understand why that ExecutionContext is needed in all
those signatures, go back and re-read section 3.3 and don’t
come back until you do.
4.1. Sequencing #
Let’s redefine our function from section 3 in terms of Future:
import scala.concurrent.{Future, ExecutionContext}
def timesTwo(n: Int)(implicit ec: ExecutionContext): Future[Int] =
Future(n * 2)
// Usage
{
import scala.concurrent.ExecutionContext.Implicits.global
timesTwo(20).onComplete { result => println(s"Result: $result") }
//=> Result: Success(40)
}
Easy enough, the Future.apply builder executes the given computation
on the given ExecutionContext. So on the JVM, assuming the global
execution context, it’s going to run on a different thread.
Now to do sequencing like in section 3.1:
def timesFour(n: Int)(implicit ec: ExecutionContext): Future[Int] =
for (a <- timesTwo(n); b <- timesTwo(n)) yield a + b
// Usage
{
import scala.concurrent.ExecutionContext.Implicits.global
timesFour(20).onComplete { result => println(s"Result: $result") }
//=> Result: Success(80)
}
Easy enough. That “for comprehension” magic right there is
translated to nothing more than calls to flatMap and map, being
literally equivalent with:
def timesFour(n: Int)(implicit ec: ExecutionContext): Future[Int] =
timesTwo(n).flatMap { a =>
timesTwo(n).map { b =>
a + b
}
}
And if you import scala-async in your project, then you can do it like:
import scala.async.Async.{async, await}
def timesFour(n: Int)(implicit ec: ExecutionContext): Future[Int] =
async {
val a = await(timesTwo(a))
val b = await(timesTwo(b))
a + b
}
The scala-async library is powered by macros and will translate your
code to something equivalent to flatMap and map calls. So in other
words await does not block threads, even though it gives the
illusion that it does.
This looks great actually, unfortunately it has many limitations. The
library cannot rewrite your code in case the await is inside an
anonymous function and unfortunately Scala code is usually full of
such expressions. This does not work:
// BAD SAMPLE
def sum(list: List[Future[Int]])(implicit ec; ExecutionContext): Future[Int] =
async {
var sum = 0
// Nope, not going to work because "for" is translated to "foreach"
for (f <- list) {
sum += await(f)
}
}
This approach gives the illusion of having first-class
continuations, but these continuations are unfortunately not first
class, being just a compiler-managed rewrite of the code. And yes,
this restriction applies to C# and ECMAScript as well. Which is a
pity, because it means async code will not be heavy on FP.
Remember my rant from above about the no silver bullet? 😞
4.2. Parallelism #
Just as in section 3.2 those two function calls are
independent of each other, which means that we can call them in
parallel. With Future this is easier, although its evaluation
semantics can be a little confusing for beginners:
def timesFourInParallel(n: Int)(implicit ec: ExecutionContext): Future[Int] = {
// Future is eagerly evaluated, so this will trigger the
// execution of both before the composition happens
val fa = timesTwo(n)
val fb = timesTwo(n)
for (a <- fa; b <- fb) yield a + b
// fa.flatMap(a => fb.map(b => a + b))
}
It can be a little confusing and it catches beginners off-guard. Because of its execution model, in order to execute things in parallel, you simply have to initialize those future references before the composition happens.
An alternative would be to use Future.sequence, which works for
arbitrary collections:
def timesFourInParallel(n: Int)(implicit ec: ExecutionContext): Future[Int] =
Future.sequence(timesTwo(n) :: timesTwo(n) :: Nil).map(_.sum)
This too can catch beginners by surprise, because those futures are
going to be executed in parallel only if the collection given to
sequence is strict (not like Scala’s Stream or some Iterator). And
the name is sort of a misnomer obviously.
4.3. Recursivity #
The Future type is entirely safe for recursive operations (because
of the reliance on the ExecutionContext for executing callbacks). So
retrying the sample in section 3.3:
def mapBoth[A,B,R](fa: Future[A], fb: Future[B])(f: (A,B) => R)
(implicit ec: ExecutionContext): Future[R] = {
for (a <- fa; b <- fb) yield f(a,b)
}
def sequence[A](list: List[Future[A]])
(implicit ec: ExecutionContext): Future[List[A]] = {
val seed = Future.successful(List.empty[A])
list.foldLeft(seed)((acc,f) => for (l <- acc; a <- f) yield a :: l)
.map(_.reverse)
}
// Invocation
{
import scala.concurrent.ExecutionContext.Implicits.global
sequence(List(timesTwo(10), timesTwo(20), timesTwo(30))).foreach(println)
// => List(20, 40, 60)
}
And this time we get no StackOverflowError:
val list = 0.until(10000).map(timesTwo).toList
sequence(list).foreach(r => println(s"Sum: ${r.sum}"))
//=> Sum: 99990000
4.4. Performance Considerations #
The trouble with Future is that each call to onComplete will use
an ExecutionContext for execution and in general this means that a
Runnable is sent in a thread-pool, thus forking a (logical) thread.
If you have CPU-bounded tasks, this implementation detail is actually
a disaster for performance because jumping threads means
context switches,
along with the CPU
cache locality
being destroyed. Of course, the implementation does have certain optimizations,
like the flatMap implementation using an internal execution context that’s
trampolined, in order to avoid forks when chaining those internal
callbacks, but it’s not enough and benchmarking doesn’t lie.
Also due to it being memoized means that upon completion the
implementation is forced to execute at least one
AtomicReference.compareAndSet per producer, plus one compareAndSet
call per listener registered before the Future is complete. And such
calls are quite expensive, all because we need memoization that plays
well with multithreading.
In other words if you want to exploit your CPU to its fullest for CPU-bound tasks, then working with futures and promises is not such a good idea.
If you want to see how Scala’s Future implementation compares with
Task, see the following
recent benchmark:
[info] Benchmark (size) Mode Cnt Score Error Units
[info] FlatMap.fs2Apply 10000 thrpt 20 291.459 ± 6.321 ops/s
[info] FlatMap.fs2Delay 10000 thrpt 20 2606.864 ± 26.442 ops/s
[info] FlatMap.fs2Now 10000 thrpt 20 3867.300 ± 541.241 ops/s
[info] FlatMap.futureApply 10000 thrpt 20 212.691 ± 9.508 ops/s
[info] FlatMap.futureSuccessful 10000 thrpt 20 418.736 ± 29.121 ops/s
[info] FlatMap.futureTrampolineEc 10000 thrpt 20 423.647 ± 8.543 ops/s
[info] FlatMap.monixApply 10000 thrpt 20 399.916 ± 15.858 ops/s
[info] FlatMap.monixDelay 10000 thrpt 20 4994.156 ± 40.014 ops/s
[info] FlatMap.monixNow 10000 thrpt 20 6253.182 ± 53.388 ops/s
[info] FlatMap.scalazApply 10000 thrpt 20 188.387 ± 2.989 ops/s
[info] FlatMap.scalazDelay 10000 thrpt 20 1794.680 ± 24.173 ops/s
[info] FlatMap.scalazNow 10000 thrpt 20 2041.300 ± 128.729 ops/s
As you can see the Monix Task destroys
Scala’s Future for CPU-bound tasks.
NOTE: this benchmark is limited, there are still use-cases where
usage of Future is faster (e.g. the Monix Observer
uses Future for back-pressure for a good reason) and performance is
often not relevant, like when doing I/O, in which case throughput
will not be CPU-bound.
5. Task, Scala’s IO Monad #
Task is a data type for controlling possibly lazy & asynchronous computations,
useful for controlling side-effects, avoiding nondeterminism and callback-hell.
The Monix library provides a very sophisticated Task implementation, inspired by the Task in Scalaz. Same concept, different implementation.
The Task type is also inspired by Haskell’s IO monad,
being in this author’s opinion the true IO type for Scala.
This is a matter of debate, as Scalaz also exposes a separate IO type
that only deals with synchronous execution. The Scalaz IO is not async, which
means that it doesn’t tell the whole story, because on top of the JVM you need
to represent async computations somehow. In Haskell on the other hand you have
the Async type which is converted to IO, possibly managed by the runtime
(green-threads and all).
On the JVM, with the Scalaz implementation, we can’t represent async
computations with IO and without blocking threads on evaluation, which is
something to avoid, because
blocking threads is error prone.
In summary the Task type:
- models lazy & asynchronous evaluation
- models a producer pushing only one value to one or multiple consumers
- it is lazily evaluated, so compared with
Futureit doesn’t trigger the execution, or any effects untilrunAsync - it is not memoized by default on evaluation, but the Monix
Taskcan be - doesn’t necessarily execute on another logical thread
Specific to the Monix implementation:
- allows for cancelling of a running computation
- never blocks any threads in its implementation
- does not expose any API calls that can block threads
- all async operations are stack safe
A visual representation of where Task sits in the design space:
| Eager | Lazy | |
|---|---|---|
| Synchronous | A | () => A |
| Coeval[A], IO[A] | ||
| Asynchronous | (A => Unit) => Unit | (A => Unit) => Unit |
| Future[A] | Task[A] |
5.1. Sequencing #
Redefining our function from section 3 in terms of Task:
import monix.eval.Task
def timesTwo(n: Int): Task[Int] =
Task(n * 2)
// Usage
{
// Our ExecutionContext needed on evaluation
import monix.execution.Scheduler.Implicits.global
timesTwo(20).foreach { result => println(s"Result: $result") }
//=> Result: 40
}
The code seems to be almost the same as the Future version in
section 4.1, the only difference is that our timesTwo
function no longer takes an ExecutionContext as a parameter.
This is because Task references are lazy, being like functions,
so nothing gets printed until the call to foreach which forces
the evaluation to happen. It is there that we need a
Scheduler,
which is Monix’s enhanced ExecutionContext.
Now to do sequencing like in section 3.1:
def timesFour(n: Int): Task[Int] =
for (a <- timesTwo(n); b <- timesTwo(n)) yield a + b
// Usage
{
// Our ExecutionContext needed on evaluation
import monix.execution.Scheduler.Implicits.global
timesFour(20).foreach { result => println(s"Result: $result") }
//=> Result: 80
}
And just like with the Future type, that “for comprehension” magic
is translated by the Scala compiler to nothing more than calls to
flatMap and map, literally equivalent with:
def timesFour(n: Int): Task[Int] =
timesTwo(n).flatMap { a =>
timesTwo(n).map { b => a + b }
}
5.2. Parallelism #
The story for Task and parallelism is better than with Future, because
Task allows fine-grained control when forking tasks, while trying
to execute transformations (e.g. map, flatMap) on the current thread
and call-stack, thus preserving cache locality and avoiding context
switches for what is in essence sequential work.
But first, translating the sample using Future does not work:
// BAD SAMPLE (for achieving parallelism, as this will be sequential)
def timesFour(n: Int): Task[Int] = {
// Will not trigger execution b/c Task is lazy
val fa = timesTwo(n)
val fb = timesTwo(n)
// Evaluation will be sequential b/c of laziness
for (a <- fa; b <- fb) yield a + b
}
In order to achieve parallelism Task requires you to be explicit about it:
def timesFour(n: Int): Task[Int] =
Task.mapBoth(timesTwo(n), timesTwo(n))(_ + _)
Oh, does mapBoth seem familiar? If those two tasks fork threads on
execution, then they will get executed in parallel as mapBoth starts
them both at the same time.
5.3. Recursivity #
Task is recursive and stack-safe (in flatMap) and incredibly efficient, being powered
by an internal trampoline. You can checkout this cool paper by Rúnar Bjarnason on
Stackless Scala with Free Monads
for getting a hint on how Task got implemented so efficiently.
The sequence implementation looks similar with the one for Future
in section 4.3, except that you can see the laziness in
the signature of sequence:
def sequence[A](list: List[Task[A]]): Task[List[A]] = {
val seed = Task.now(List.empty[A])
list.foldLeft(seed)((acc,f) => for (l <- acc; a <- f) yield a :: l)
.map(_.reverse)
}
// Invocation
{
// Our ExecutionContext needed on evaluation
import monix.execution.Scheduler.Implicits.global
sequence(List(timesTwo(10), timesTwo(20), timesTwo(30))).foreach(println)
// => List(20, 40, 60)
}
6. Functional Programming and Type-classes #
When working with well grown functions such as map, flatMap and mapBoth,
we no longer care that underlying it all is an “(A => Unit) => Unit”, because these
functions are, assuming lawfulness, pure and referentially transparent.
This means we can reason about them and their result, divorced from their
surrounding context.
This is the great achievement of Haskell’s IO. Haskell does not “fake” side-effects,
as functions returning IO values are literally pure, the side-effects being
pushed at the edges of the program where they belong. And we can say the same
thing about Task. Well, for Future it’s more complicated given its eager
nature, but working with Future is not bad either.
And can we build interfaces that abstract over such types as Task, Future,
Coeval, Eval, IO, Id, Observable and others?
Yes we can, we’ve already seen that flatMap describes sequencing, while
mapBoth describes parallelism. But we can’t describe them with classic
OOP interfaces, for one because due to the covariance and contravariance rules of
Function1 parameters we’d lose type info in flatMap (unless you use
F-bounded polymorphic types, which are more suitable for implementation reuse and
aren’t available in other OOP languages),
but also because we need to describe a data constructor that can’t be a
method (i.e. OOP subtyping applies to instances and not whole classes).
Fortunately Scala is one of the very few languages capable of higher kinded types and with the ability to encode type-classes, which means we’ve got everything needed to port concepts from Haskell 😄
Author’s Rant: The dreaded Monad, Applicative and Functor words
strike fear in the hearts of the unfaithful, having given rise to the belief
that they are “academic” notions disconnected from real-world concerns,
with book authors going to great length to avoid using these words, which
includes Scala’s API documentation and official tutorials.
But this is a disservice to both the Scala language and its users.
In other languages they are only design patterns that are hard to explain
primarily because they can’t be expressed as types. You can count the
languages having this expressive capability with one hand. And users suffer
because in case of trouble they don’t know how to search for existing
literature on the subject, having been deprived of learning
the correct jargon.
I also feel this is a flavor of
anti-intellectualism,
as usual born out of fear of the unknown. You can see it coming from people
that really know what they are doing, as none of us is immune. For example Java’s
Optional
type violates the functor laws (e.g. opt.map(f).map(g) != opt.map(f andThen g)),
in Swift 5 == Some(5) which is preposterous and good luck explaining to
people that Some(null) actually makes sense for as long as null is a valid
value of AnyRef and because otherwise you can’t define Applicative[Option].
6.1. Monad (Sequencing and Recursivity) #
This article is not about explaining Monads. There are other great articles
for that. But if you’re looking to build an intuition, here’s another one: in the
context of data types such as Future or Task, Monads describe sequencing
of operations and is the only reliable way to ensure ordering.
“Observation: programmers doing concurrency with imperative languages are tripped by the unchallenged belief that “;” defines sequencing.” – Aleksey Shipilëv
A simple encoding of the Monad type in Scala:
// We shouldn't need to do this :-(
import scala.language.higherKinds
trait Monad[F[_]] {
/** Constructor (said to lift a value `A` in the `F[A]`
* monadic context). Also part of `Applicative`, see below.
*/
def pure[A](a: A): F[A]
/** FTW */
def flatMap[A,B](fa: F[A])(f: A => F[B]): F[B]
}
And providing an implementation for Future:
import scala.concurrent._
// Supplying an instance for Future isn't clean, ExecutionContext needed
class FutureMonad(implicit ec: ExecutionContext)
extends Monad[Future] {
def pure[A](a: A): Future[A] =
Future.successful(a)
def flatMap[A,B](fa: Future[A])(f: A => Future[B]): Future[B] =
fa.flatMap(f)
}
object FutureMonad {
implicit def instance(implicit ec: ExecutionContext): FutureMonad =
new FutureMonad
}
This is really powerful stuff. We can now describe a generic function
that works with Task, Future, IO, whatever, although it would be
great if the flatMap operation is stack-safe:
/** Calculates the N-th number in a Fibonacci series. */
def fib[F[_]](n: Int)(implicit F: Monad[F]): F[BigInt] = {
def loop(n: Int, a: BigInt, b: BigInt): F[BigInt] =
F.flatMap(F.pure(n)) { n =>
if (n <= 1) F.pure(b)
else loop(n - 1, b, a + b)
}
loop(n, BigInt(0), BigInt(1))
}
// Usage:
{
// Needed in scope
import FutureMonad.instance
import scala.concurrent.ExecutionContext.Implicits.global
// Invocation
fib[Future](40).foreach(r => println(s"Result: $r"))
//=> Result: 102334155
}
PRO-TIP: this is just a toy example. For getting serious, see Typelevel’s Cats
6.2. Applicative (Parallelism) #
Monads define sequencing of operations, but sometimes we want to compose the results of computations that are independent of each other, that can be evaluated at the same time, possibly in parallel. There’s also a case to be made that applicatives are more composable than monads 😏
Let’s expand our mini Typeclassopedia to put on your wall:
trait Functor[F[_]] {
/** I hope we are all familiar with this one. */
def map[A,B](fa: F[A])(f: A => B): F[B]
}
trait Applicative[F[_]] extends Functor[F] {
/** Constructor (lifts a value `A` in the `F[A]` applicative context). */
def pure[A](a: A): F[A]
/** Maps over two references at the same time.
*
* In other implementations the applicative operation is `ap`,
* but `map2` is easier to understand.
*/
def map2[A,B,R](fa: F[A], fb: F[B])(f: (A,B) => R): F[R]
}
trait Monad[F[_]] extends Applicative[F] {
def flatMap[A,B](fa: F[A])(f: A => F[B]): F[B]
}
And to expand our Future implementation:
// Supplying an instance for Future isn't clean, ExecutionContext needed
class FutureMonad(implicit ec: ExecutionContext)
extends Monad[Future] {
def pure[A](a: A): Future[A] =
Future.successful(a)
def flatMap[A,B](fa: Future[A])(f: A => Future[B]): Future[B] =
fa.flatMap(f)
def map2[A,B,R](fa: Future[A], fb: Future[B])(f: (A,B) => R): Future[R] =
// For Future there's no point in supplying an implementation that's
// not based on flatMap, but that's not the case for Task ;-)
for (a <- fa; b <- fb) yield f(a,b)
}
object FutureMonad {
implicit def instance(implicit ec: ExecutionContext): FutureMonad =
new FutureMonad
}
So we can now define generic functions based on Applicative which is going
to work for Future, Task, etc:
def sequence[F[_], A](list: List[F[A]])
(implicit F: Applicative[F]): F[List[A]] = {
val seed = F.pure(List.empty[A])
val r = list.foldLeft(seed)((acc,e) => F.map2(acc,e)((l,a) => a :: l))
F.map(r)(_.reverse)
}
PRO-TIP: worth repeating, this is just a toy example. For getting serious, see Typelevel’s Cats
6.3. Can We Define a Type-class for Async Evaluation? #
Missing from above is a way to actually trigger an evaluation and
get a value out. Thinking of Scala’s Future, we want a way to abstract
over onComplete. Thinking of Monix’s Task we want to abstract over runAsync.
Thinking of Haskell’s and Scalaz’s IO, we want a way to abstract over
unsafePerformIO.
The FS2 library has defined a type-class called Effect that goes like this (simplified):
trait Effect[F[_]] extends Monad[F] {
def unsafeRunAsync[A](fa: F[A])(cb: Try[A] => Unit): Unit
}
This looks like our initial Async type, very much similar with
Future.onComplete, with Task.runAsync and could be applied to
IO.unsafePerformIO.
However, this is not a real type-class because:
- it is lawless and while that’s not enough to disqualify it (after all,
useful lawless type-classes like
Showexist), the bigger problem is … - as shown in section 3.3, in order to avoid the Wrath of
StackOverflowError, we need some sort of execution context or thread-pool that can execute tasks asynchronously without blowing up the stack
And such an execution context is different from implementation to implementation.
Java will use Executor, the Scala Future uses ExecutionContext, Monix
uses Scheduler which is an enhanced ExecutionContext, FS2 and Scalaz
use Strategy which wraps an Executor for forking threads and don’t inject
a context when their unsafePerformIO or runAsync gets called
(which is why many of the Scalaz combinators are in fact unsafe), etc.
We could apply the same strategy as with Future, to build the type-class
instance by taking a implicit whatever: Context from the scope. But that’s
a little awkward and inefficient. It’s also telling that we can’t define
flatMap only in terms of Effect.unsafePerformIO, not without that
execution context. And if we can’t do it, then the type should probably
not inherit from Monad because it’s not necessarily a Monad.
So I’m personally not sure - if you have suggestions for what should be introduced in Cats, I’d love to hear them.
I do hope you enjoyed this thought experiment, designing things is fun 😎
7. Picking the Right Tool #
Some abstractions are more general purpose than others and personally I think the mantra of “picking the right tool for the job” is overused to defend poor choices.
That said, there’s this wonderful presentation by Rúnar Bjarnason called Constraints Liberate, Liberties Constrain that really drives the point home with concurrency abstractions at least.
As said, there is no silver bullet that can be generally applied for dealing with concurrency.
The more high-level the abstraction, the less scope it has in solving issues. But the less scope
and power it has, the simpler and more composable the model is.
For example many developers in the Scala community are overusing Akka Actors -
which is a great library, but not when misapplied. Like don’t use an
Akka Actor when a Future or a Task would do. Ditto for other abstractions,
like the Observable pattern in Monix and ReactiveX.
Also learn by heart these 2 very simple rules:
- avoid dealing with callbacks, threads and locks, because they are very error prone and not composable at all
- avoid concurrency like the plague it is
And let me tell you, concurrency experts are first of all experts in avoiding concurrency 💀