Monifu vs Akka Streams
Back in June I attended Scala Days in Amsterdam and participated at a talk by Mathias Doenitz on The Reactive Streams Implementation Landscape. It was a good talk, yet I felt a little bias towards Akka Streams, which is natural coming from somebody that is contributing to Akka, but let me give you the perspective from the other side.

For a short introduction, we are talking about libraries that are meant for stream processing. Several libraries exist for stream processing, a craze that started with Rx.NET, or with Iteratees on the Haskell side and since then we ended up with ports and enhancements, like RxJava, Rx.js, Bacon.js, Play’s Iteratees, Scalaz Streams and more recently Akka Streams.
The library I’ve been working on is named Monifu. It has just reached 1.0-RC1, it is built on idiomatic Scala principles, is cross-compiled to Scala.js, is freaking awesome and even though it is inspired by Rx, compared to other Rx implementations, it was designed from scratch to deal with back-pressure. It’s also implementing the 1.0 version of the Reactive Streams protocol for interoperability. Checkout this cool sample of client/server communications, where both the server-side and the browser-side is handled by Monifu: code / demo (that’s a free Heroku node, go easy on it :-)).
Code #
I am biased, I admit. But personally I find the design of Akka Streams to be conceptually ugly.
Mathias was kind to release his comparison on GitHub, containing the same problem solved with Akka Streams, RxJava and Reactor and I think this provides a good starting point for a comparison. So lets take Mathias’s own sample for Akka Streams and compare it with my own sample for Monifu. Akka Streams is missing some useful operators, like operators for throttling, therefore the code needs to implement it.
To throttle once per second, here’s what the Akka Streams sample is doing:
// Akka Streams sample
def onePerSecValve: Flow[State, State, Unit] =
Flow() { implicit b ⇒
import FlowGraph.Implicits._
val zip = b.add(ZipWith[State, Tick.type, State](Keep.left)
.withAttributes(OperationAttributes.inputBuffer(1, 1)))
val dropOne = b.add(Flow[State].drop(1))
Source(Duration.Zero, 1.second, Tick) ~> zip.in1
zip.out ~> dropOne.inlet
(zip.in0, dropOne.outlet)
}
Monifu has throttling operators built-in, but if that weren’t the case, here’s how you could implement sampling per second:
// Monifu sample
def throttleOnePerSec[T](source: Observable[T]): Observable[T] = {
val tick = Observable.intervalAtFixedRate(1.second, 1.second)
source.whileBusyDropEvents.zip(tick)
.map { case (elem, _) => elem }
}
Both pieces of code are doing roughly the same thing. A different
data-source is being started that generates a tick over every second
and that data-source is being zipped with our source. Events emitted
by our source are dropped as long as the tick is silent and then when
the tick event happens we emit whatever we’ve got. Using zip for
sampling is actually very inefficient, as zip is a fundamentally
concurrent operator, but this is just for comparing apples with apples
;-)
So why is the code for Akka Streams looking so complicated? Well
that’s because of its design, but lets come back to that later.
In the Akka Streams sample, here’s how the original data-source is
being split in two streams (filterInner and filterOuter) and then
merged:
// Akka Streams sample
Source(() ⇒ new RandomDoubleValueGenerator())
.grouped(2)
.map { case x +: y +: Nil ⇒ Point(x, y) }
.via(broadcastFilterMerge)
// ...
def broadcastFilterMerge: Flow[Point, Sample, Unit] =
Flow() { implicit b ⇒
import FlowGraph.Implicits._
val broadcast = b.add(Broadcast[Point](2)) // split one upstream into 2 downstreams
val filterInner = b.add(Flow[Point].filter(_.isInner).map(InnerSample))
val filterOuter = b.add(Flow[Point].filter(!_.isInner).map(OuterSample))
val merge = b.add(Merge[Sample](2)) // merge 2 upstreams into one downstream
broadcast.out(0) ~> filterInner ~> merge.in(0)
broadcast.out(1) ~> filterOuter ~> merge.in(1)
(broadcast.in, merge.out)
}
Here’s Monifu’s version, doing the same thing.
// Monifu sample
val source = Observable
.fromIterator(new RandomDoubleValueGenerator())
.buffer(2)
.map { case Seq(x, y) ⇒ Point(x, y) }
.share() // shares the data-source
val innerSamples = source.filter(_.isInner).map(InnerSample)
val outerSamples = source.filter(!_.isInner).map(OuterSample)
Observable.merge(innerSamples, outerSamples)
At this point I think a pattern emerges.
Design #
A stream of information is like a river. Does the river care who observes it or who drinks from it? No, it doesn’t. And yes, sometimes you need to share the source between multiple listeners, sometimes you want to create new sources for each listener. But the listener shouldn’t care what sort of producer it has on its hands or vice-versa. And people are really not good at reasoning about graphs and making those graphs explicit doesn’t make it better, it makes it worse.

In Monifu / Rx you’ve got hot observables (hot data sources shared
between an unlimited number of subscribers) and cold observables (each
subscriber gets its very own private data source). You can also
convert any cold data source into a hot one by using the multicast
operator, in combination with Subjects that dictate behavior
(e.g. Publish, Behavior, Async or Replay). The
ConnectableObservable
is meant for hot data sources. In our sample above, we are using
share(), an operator that transforms our data source into a hot one
and then applies reference counting on its subscribers to know when to
stop it. This is what encapsulation is all about.
In Akka Streams the sources have a “single output” port and what you
do is you build “flow graphs” and sinks. Akka Streams is thus all
about modeling how streams are split. They call it “explicit
fan-out” and it’s a design choice. However I consider it an
encapsulation leak that makes things way more complicated than they
should be and defeats the purpose of using a library for streams
manipulation in the first place. In Rx (Rx.NET / RxJava / Monifu)
terms, this is like having single-subscriber Observables and then
working with Subjects (which is both a listener and a producer) and
people that have used Rx know that working with Subjects sucks and
when you do, you usually encapsulate it really, really well. This
design choice of Akka Streams has also leaked into the “Reactive
Streams” specification, as that Processor interface is irrelevant,
plus during the talks on what the Producer should be, the original
design was for the Producer to be single-subscriber.
Another thing I don’t like is that Akka Streams depends on Akka, the
library. You need an Actor System and an ActorFlowMaterializer,
whatever that is, with the tasks being executed by actors. I think
that’s a design mistake. One reason for why Scala’s Future and
ExecutionContext are great is precisely because they model only
asynchronous computations, but are completely oblivious to how the
required asynchronous execution happens. This
is why Future works on top of Scala.js without problems.
And again, I’m biased, but Monifu’s own implementation is conceptually
elegant. You’ve got the
Scheduler
that is used to execute tasks (an evolved ExecutionContext), the
Observable
interface which is the producer, characterized solely by its
onSubscribe function, then you’ve got the
Observer
which represents the consumer and has the back-pressure protocol baked
in its API, the
Subject
that is both a producer and a consumer, the
Channel
which represents a way to build Observables in an imperative way
without back-pressure concerns and the
ConnectableObservable,
which represents hot data-sources that are shared between multiple
subscribers. Monifu’s internals are self-explanatory and (I hope) a
joy to go through.
I mean, this beauty describes Monifu’s design and represents at least half of what you need to know (and skipping over back-pressure concerns, you already know it):
trait Observer[-T] {
def onNext(elem: T): Future[Ack]
def onError(ex: Throwable): Unit
def onComplete(): Unit
}
In contrast, I found the source-code and the concepts in Akka Streams to be very hard to read and understand. Give it a try and compare.
Performance #
I’ve left the best part of Monifu for last. Here’s running the Monifu sample:
[info] Running swave.rsc.MonifuPi
After 1,909,713 samples π is approximated as 3.14102
After 4,132,610 samples π is approximated as 3.14240
After 6,342,356 samples π is approximated as 3.14241
After 8,513,597 samples π is approximated as 3.14239
After 10,696,940 samples π is approximated as 3.14176
After 12,897,762 samples π is approximated as 3.14165
After 15,099,261 samples π is approximated as 3.14160
After 17,326,511 samples π is approximated as 3.14169
After 19,529,832 samples π is approximated as 3.14164
After 21,752,232 samples π is approximated as 3.14170
[success] Total time: 11 s, completed Sep 6, 2015 2:48:06 PM
Here’s Akka Streams:
[info] Running swave.rsc.AkkaPi
After 59,812 samples π is approximated as 3.12807
After 258,925 samples π is approximated as 3.13910
After 525,537 samples π is approximated as 3.14173
After 892,973 samples π is approximated as 3.14070
After 1,258,939 samples π is approximated as 3.14127
After 1,545,861 samples π is approximated as 3.14019
After 1,813,374 samples π is approximated as 3.14103
After 2,219,992 samples π is approximated as 3.14137
After 2,515,283 samples π is approximated as 3.14129
After 2,826,297 samples π is approximated as 3.14148
[success] Total time: 13 s, completed Sep 6, 2015 2:49:23 PM
Here’s RxJava (RxScala):
[info] Running swave.rsc.RxScalaPi
After 804,127 samples π is approximated as 3.11240
After 1,747,146 samples π is approximated as 3.12848
After 2,761,645 samples π is approximated as 3.13558
After 3,678,029 samples π is approximated as 3.13880
After 4,756,818 samples π is approximated as 3.13960
After 5,787,079 samples π is approximated as 3.14172
After 6,768,352 samples π is approximated as 3.14249
After 7,804,973 samples π is approximated as 3.14320
After 8,812,403 samples π is approximated as 3.14381
After 9,625,207 samples π is approximated as 3.14393
[success] Total time: 12 s, completed Sep 6, 2015 2:54:55 PM
The results:
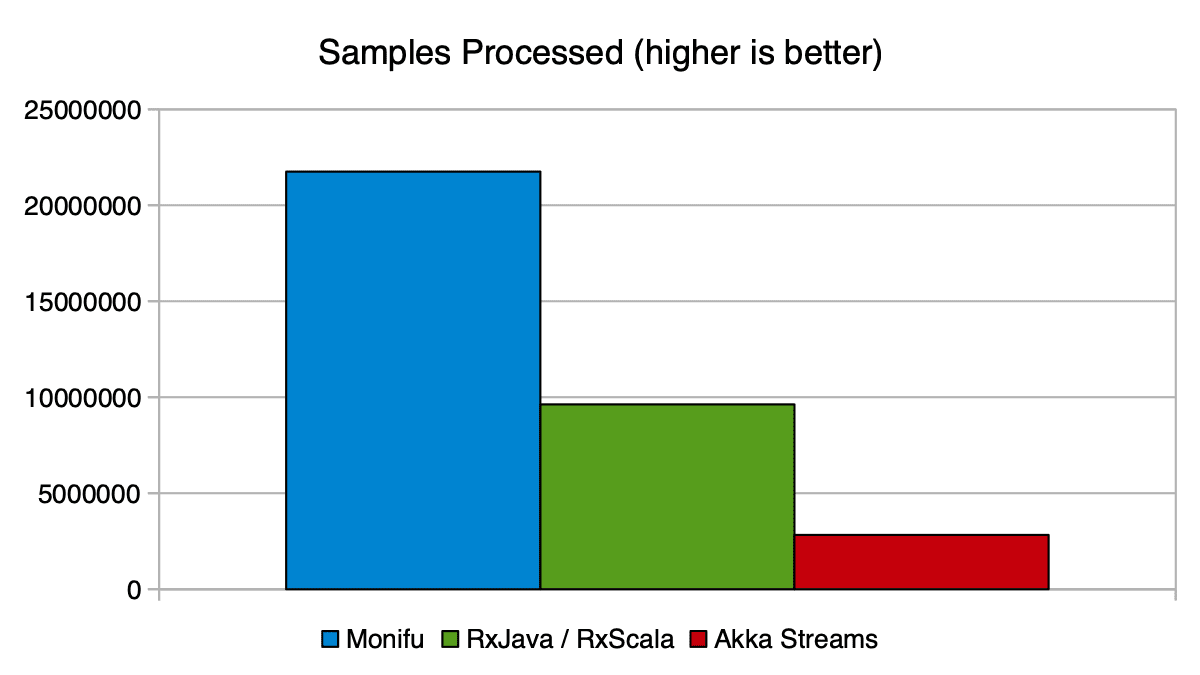
So my Monifu sample is consistently beating Akka Streams by at least a factor of 7 and RxJava/RxScala by a factor of 2.
The difference is so large that either Akka Streams has some serious improvements to achieve, or I’m doing something terribly wrong, because this is Monifu’s out-of-the-box behavior, as in I haven’t even attempted to fine tune the buffers or the scheduler for this sample.
But yes, Monifu was built for both ease of use and performance.
Final Words #
Again, I’m biased, since I’m the author of an alternative, so take this conclusion for what it is.
The precursors of Akka Streams have been Play’s Iteratees and the Akka I/O Pipeline, the former on its way to deprecation, the latter already deprecated. Unfortunately I’m seeing the same mistakes: implementation hard to read, conceptualy very complicated, while exposing custom binary operators in the hope of forming a DSL that will somehow fix this complexity. And I’m all for wheel reinvention when it’s done for the right reasons, but I find this model to be inferior to an evolved Rx (such as Monifu) and this is just one other design heading towards deprecation.
If you’re interested in Monifu, there’s still some work to be done. It’s at release candidate for version 1.0, meaning that we’re done breaking the API and a very functional core is ready. Monifu has been developed in parallel to its usage in production for the past year, should be fairly solid and has very good test coverage as testament to that, but bugs may still happen, since a lot of work went on this past month. Documentation is sadly a work in progress and for now only the API documentation is up to date. But we’re marching towards a 1.0 release you can rely on, which should be available in about two weeks from now (if everything goes well). Checkout the GitHub repo, join our chat channel and give us feedback.
Update (Sep 8, 8:00 AM) #
Some interesting questions happened on the reddit thread. To dispel some myths:
- currently Akka Streams does no more parallelism than Monifu does
- in our sample Monifu is not single-threaded
- in our sample Monifu parallelizes the portion that it can, which
is the processing of
filterInnerandfilterOuter, plus execution is jumping threads, because Monifu as a matter of policy never keeps a single thread occupied for too long - you can’t parallelize concurrent operations, that being an oxymoron, which is why I’m dumbfounded by claims of parallelism
Cheers,